Cloud repatriation. Reverse cloud migration. Unclouding (we can probably agree this one shouldn’t catch on).
All signal a growing movement in the number of businesses breaking out of hyperscale cloud as they look to claw back control over eye-watering long-terms costs and infrastructure lock-in.
Whatever your reason for leaving, the idea of migrating your infrastructure, either as a whole or in part, out of the cloud into a different ecosystem is daunting. But that shouldn’t put you off. A smart, considered cloud exit strategy that takes into account common challenges with cloud repatriation will make the process much more streamlined.
Table of contents
But what are these common challenges? And how can you mitigate against them?
A lot of customers that we work with on reverse cloud migrations just want to pick up their infrastructure and move it. But as one of our gaming customers, Andrew Walker from Gameye, described infrastructure migration – “it’s a bit like trying to change the wheels on a moving vehicle”. Taking every wheel off at once would inevitably result in disaster. Which is why a good cloud exit strategy doesn’t happen all in one go. In fact, we’ve had customers who’ve taken up to 18 months to fully migrate away from cloud.
Of course, there are always some instances where that’s not possible. For example, if you’re a startup that has built your infrastructure in a hurry and can’t decouple it from the hyperscale environment easily. You will need to spend time rearchitecting in the cloud first in order to decouple, and then you may need to lift and shift your infrastructure in one go before you can move onto your next phase of growth.
For most companies that can take the phased approach, it’s vital that you take the time to really understand your infrastructure, right down to the finer details:
How is it designed?
What products are integrated?
What servers are you using?
What is included in your monthly bill?
Which systems are coupled so tightly they can’t be in different data centers?
Only once you’ve done this work should you start to look at alternative environments. Because without that knowledge you can’t realistically figure out what your new environment needs to look like and what is involved in migrating to that new platform.
But as a general rule, to see as little impact as possible during the reverse cloud migration, identify which part of your infrastructure will likely have the least impact on day-to-day operations and migrate that first. Once completed, learn from the process - look at what worked and what didn’t – and then move onto the next stage of the migration.
In a blog detailing their cloud exit strategy SaaS provider Prerender outlined the success of a phased migration – “we avoided the dangers by carefully planning each stage of the migration, testing each stage of implementation before scaling, and making it easy to correct any errors should anything go wrong. That way, we could reap the benefits of saving on server fees while keeping any potential risks to a minimum.”
The hyperscale cloud providers are notorious for their ability to lock in companies’ infrastructure on their platforms. Meaning they make it very difficult for you to replicate exactly the same environment elsewhere - you may need to hire or contract out expertise to help you look for or create alternative solutions.
For example:
You are using an AWS scalable database product, which automatically selects the best instance types for you. Without this product in a different environment, you will need to manually select the right instance types but may not have the knowledge or experience to do so.
Similarly, some hyperscale cloud products are designed so that you can’t get like for like quotes for alternative solutions. If you’ve ever bought a platform as a service product through a hyperscale cloud provider, for example, you’ll know how incredibly intricate the set up and billing models are to account for the complexity of each product. So much so that there are people who have made their careers (and a lot of money) out of helping companies set up their environments in hyperscale cloud and decipher monthly bills. If you find yourself using products like these in in your hyperscale environment, I’d recommend hiring or working with someone who knows how to convert a certain product in hyperscale cloud into different technology.
The big takeaway here is to be prepared to explore new approaches to set ups or even new technologies. It may be that you can’t use the same database or application that you used in hyperscale in your new environment. Such as when Remoby migrated from AWS to our bare metal environment.
“Overall, the migration process went quite smoothly for us. The only challenge we faced was that in AWS, we used k8s as a service called Amazon EKS and simply added the necessary nodes to it, then configured Helm charts for our services. This didn’t work quite the same with the servers.com managed K8’s service and there was a moment when we were ready to abandon the migration idea. Fortunately, we managed to work together with the servers.com team to come up with a solution that allowed us to progress rapidly and pleasantly,” said Sergey Chernukhin, CTO of Remoby.
Andrew from Gameye has also had experience helping gaming companies with reverse cloud migration and noted that it can sometimes “involve UI changes because the matchmaker doesn’t quite work the same” in another environment as it does in the hyperscale set up. It’s important to be aware of differences like this because, in this instance, gaming companies might experience a change in the game experience if their game has already launched.
So, be prepared to carry out some adjustments to applications following migration. It’s surprising how even moving workloads between the same vendor hardware with slightly different models can cause applications to behave differently.
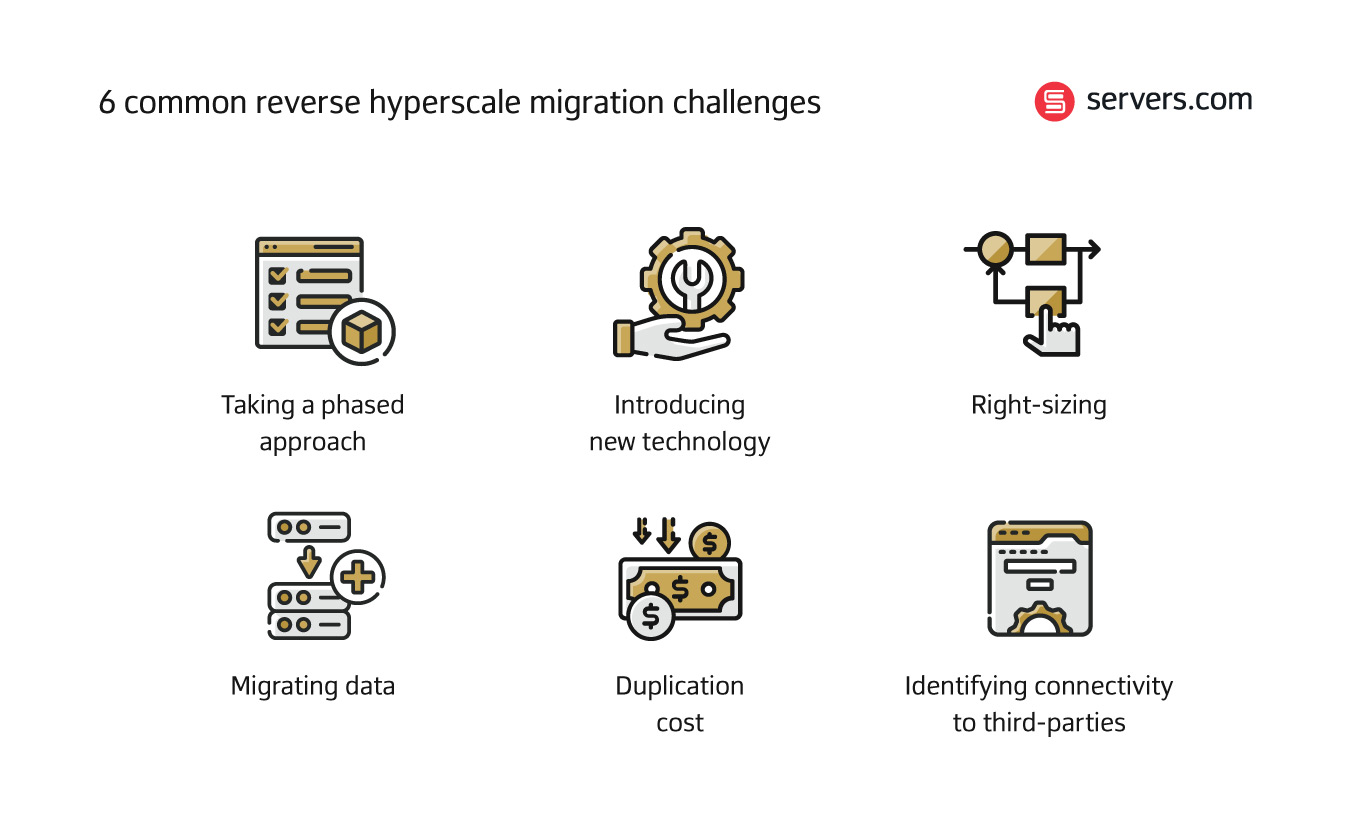
This is very closely linked to the introducing new technology challenge above. By right-sizing, I mean that when you move out of the hyperscale environment, you move onto servers that are the right size for your needs. This may sound obvious but it’s likely you will have over-provisioned or under-provisioned your ecosystem in hyperscale cloud.
As discussed above, the key is to look at and have a good understanding of the statistical data associated with your hyperscale environment so that when you migrate out you can select servers that reflect what you actually need.
If you choose to work with a hosting partner for your new environment, the planning process should include carrying out an in-depth proof of concept with that partner. It will give you the opportunity to test different machine set ups to ensure that you have the right one for you.
This is perhaps the hardest piece of the migration puzzle. Migrating data can take days and even weeks to complete, depending on how big your data set is. For some companies, this length of time may not be an issue. Or you might not even have any data to migrate, like some gaming servers which are session based and don’t retain data from each session. For most other businesses that are running 24/7 and use databases to store real-time data, time is of greater importance.
There are two main options to migrating your data out of the hyperscale environment. Which one you select depends on the type and size of your data sets.
This involves the hyperscale cloud provider uploading your data to a disk, which they’ll then pass on to you to plug into your new environment. It’s important to bear in mind with this approach that the data which is uploaded to the disk is data from a point in time. Say the data is uploaded to the disk on a Friday but isn’t then added to the new environment until the Monday, you’ve lost two-to-three days of data.
That said, it can sometimes be a quicker option than transferring data virtually if you’re transferring terabytes or even petabytes.
As the name suggests, this approach involves transferring data via the internet. It can take longer to transfer data over the internet than physically if it’s a massive data set. Even if it’s a smaller set and takes six hours to transfer, you’ve still got six hours of changes that have occurred in that time that haven’t been captured in the migration. You then need to keep transferring data to cover every difference until you’ve got it down to a point where you schedule a maintenance window with customers to transfer the remaining data.
This maintenance window point is important. As much as I would love to say that you can carry out a migration without it impacting customers in some way, it’s just not realistic. Accepting that, however, means that you can plan for it so that the impact is as minimal as possible. Whichever data migration path you choose, include at least one planned maintenance and communicate it clearly to customers well in advance.
Most migration projects follow a similar process. First you spin up infrastructure in the new environment whilst retaining your main production set up in the hyperscale cloud provider. Once that’s done, you bring the servers online – add networking, install the operating system and hypervisors (if you’re in a virtual environment), build out the application stacks and configure everything.
What this means is that you will - for a period of time depending on the size and complexity of the ecosystem that you are migrating – need to pay for two infrastructure environments at the same time. This is to ensure that the ecosystem is running correctly in its new environment and allow for the migration of your previous infrastructure to be fully complete.
For trading platform FxGrow, “it took us two weeks to fully migrate to the new hosting provider. We were paying our previous hosting provider and paying our new hosting provider until the migration finished”. Their migration time frame was dictated by a key application that the company uses – MetaTrader 5 – to ensure that there would be as minimal downtime as possible during the migration period.
Side by side migration is the norm and so, therefore, are duplication costs. But if you haven’t planned for them, it will of course raise its head as a challenge at some point in the migration project. To avoid this, build duplication costs in right at the start of the process. When you are working up a plan and budget for the migration, put a line item in your budget that accounts for a period of crossover.
If you have applications that require consistent uptime, follow FxGrow’s example and speak to the providers of that application for their recommendation on migration time.
Most company’s infrastructure ecosystems aren’t just supported by internal connectivity but are connected to multiple third-party providers. The larger the organization, the more organically evolved it will have become over the years and it’s likely you will have third-party connections you’re not even aware of.
For most adtech providers, for example, their traffic comes from partners so if they change their IP address they have to notify their partners and there is likely to be an SLA around them transferring to the new IP.
As part of the migration planning process, carry out a thorough audit of all your third-party connections and document them clearly.
If you choose to work with a partner to host your new infrastructure environment – such as an infrastructure as a service (IaaS) provider – they will work with you to put a plan in place to ensure that every third-party connection is migrated successfully.
All six of these challenges have one overriding theme – planning.
Migration isn’t something that companies do regularly. In fact, the system administrator in charge of carrying out the migration may not have done one in years.
Which is why a successful reverse cloud migration to bare metal, on-premises and colocation needs you to plan and then plan again until you feel like you have a response for any issue or eventuality that might arise.
Whichever route you choose to go down, be prepared to put the research, time and money into creating a cloud exit strategy that you feel confident will cause the least downtime for you and your customers.
At the end of the tunnel is greater independence, flexibility, and a much more comfortable infrastructure bill.